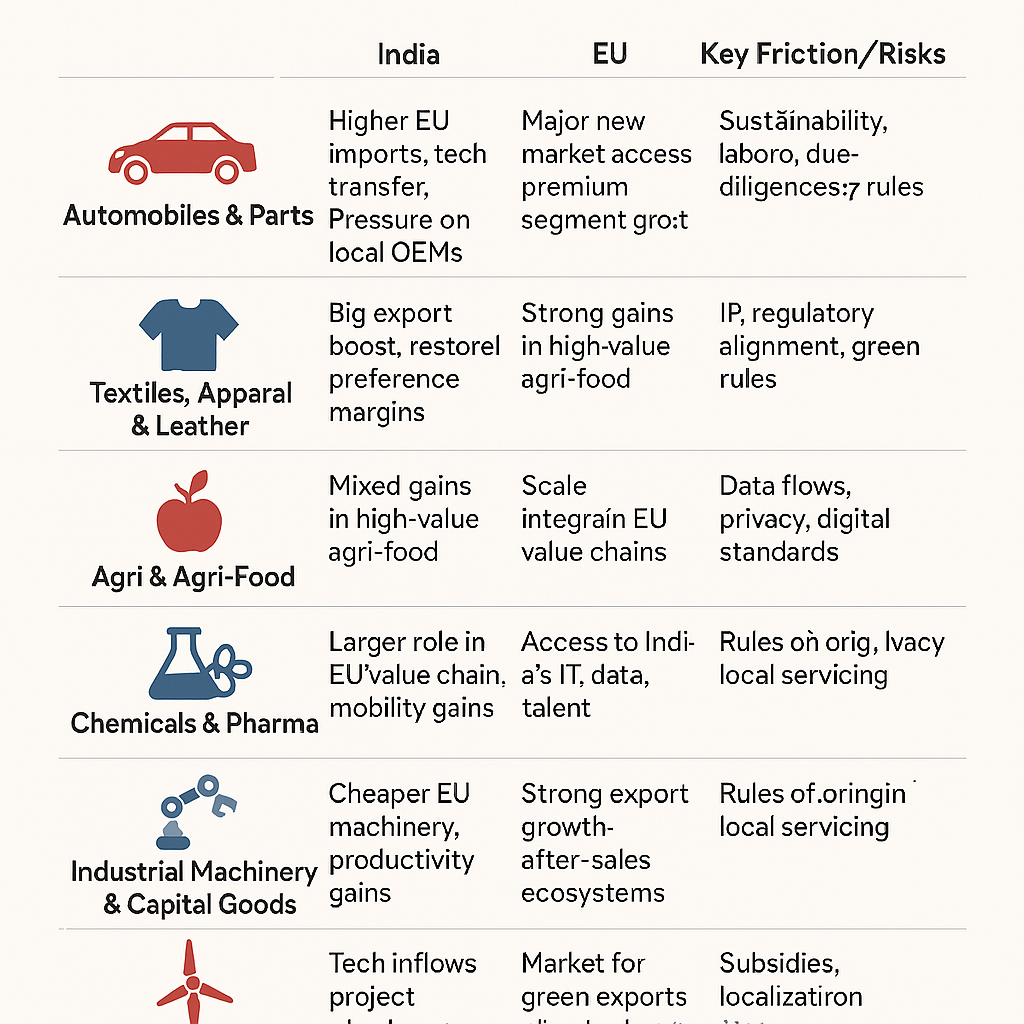
Here's a fully detailed comparison of Nvidia's AI accelerators—L2 PCIe, L20 PCIe, H20, H200 and the upcoming Huawei's Ascend 920 capable of various AI workloads, from entry-level inference to high-end training and large language model (LLM) deployment. These product are manufactured by Nvidia and Huawei companies.
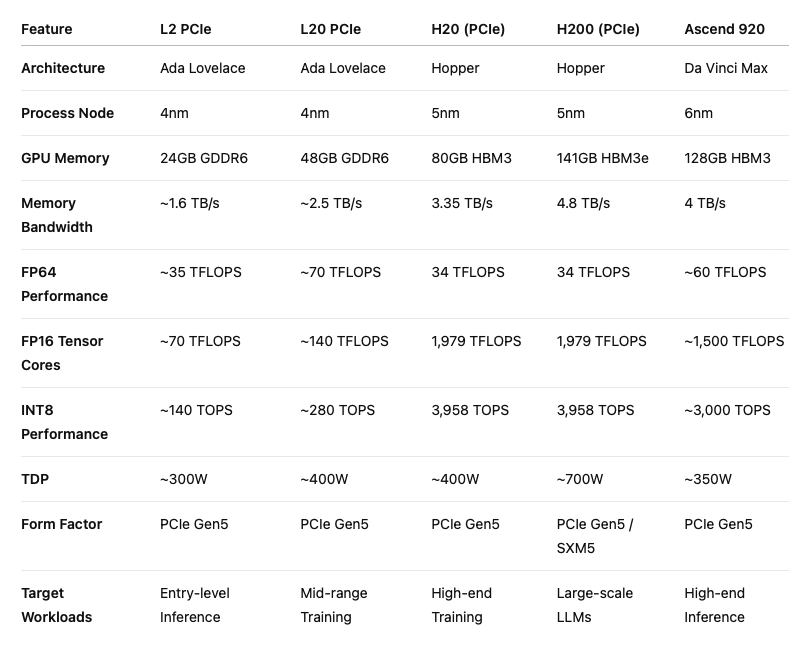
Performance & Use Cases
- L2 PCIe: Designed for entry-level inference tasks, offering efficient performance for smaller models and edge applications.
- L20 PCIe: Suited for mid-range training workloads, providing a balance between performance and power efficiency.
- H20 (PCIe): Targets high-end training scenarios, excelling in tasks like large-scale model training with substantial memory bandwidth.
- H200 (PCIe): Optimized for large language models (LLMs) and generative AI applications, delivering superior performance with 141GB HBM3e memory and 4.8 TB/s bandwidth.
- Ascend 920: Huawei's response to Nvidia's H20, featuring 128GB HBM3 memory and 4 TB/s bandwidth, targeting high-end inference workloads.
Market Targeting
- L2 PCIe: Ideal for edge devices, entry-level servers, and applications requiring low-latency inference.
- L20 PCIe: Suitable for mid-tier data centers and enterprises focusing on balanced training and inference capabilities.
- H20 (PCIe): Geared towards research institutions and enterprises conducting large-scale AI model training.
- H200 (PCIe): Tailored for organizations deploying advanced LLMs and generative AI solutions at scale.
- Ascend 920: Aimed at the Chinese market, providing an alternative to Nvidia's offerings amidst export restrictions.
Summary
- Entry-Level Inference: L2 PCIe is the go-to choice for cost-effective, low-latency applications.
- Mid-Range Training: L20 PCIe offers a balance between performance and power efficiency for moderate training tasks.
- High-End Training: H20 PCIe excels in large-scale model training with its substantial memory bandwidth.
- Large-Scale LLMs: H200 PCIe stands out with its advanced memory architecture, making it ideal for generative AI applications.
- High-End Inference: Ascend 920 provides a competitive alternative in the high-end inference space, particularly within China.
Each accelerator is tailored to specific AI workloads, ensuring optimized performance across various applications.